
Knowledge Distillation in Recommendation Systems

Background
State-of-the-art (SOTA) Recommendation Systems (RecSys) need to surface highly relevant items for a user-query from an underlying pool of millions of items in less than a second.
To find the relevance of even one given item one needs a sophisticated deep neural network (DNN) to predict the “likeability” of that item for the user. These DNNs are enormous and have billions of parameters, and require 10s of GB of memory. This makes running just a single forward pass computationally expensive, let alone running the forward pass for millions of items.
To address this issue, most SOTA RecSys deploy a 3 step approach, whereby they break the RecSys into 3 stages namely:
Generators - One or many generators that use simple models, and approx nearest neighbor (ANN) to quickly select thousands of candidates to be passed onto the next stage. Note ANN algorithms use precomputed item embedding to make computation much more tractable.
Early stage ranker (ESR) - A more complex but still simpler model to further rank thousands of candidates from the output of generator stage and filter them to hundreds.
Late stage ranker (LSR) - A full blown model that is run only on hundreds of candidates from the output of ESR.
Knowledge Distillation
As Generators and ESR use simpler models they capture less information in the training data as compared to LSR models. This means RecSys performance could be improved if the earlier stages could learn from the LSR knowledge. Achieving this is called knowledge distillation (KD). KD is typically achieved via the teacher-student training paradigm, where teacher is the LSR model, and student is the ESR model. In this set up in addition to training the student model on user defined hard labels, we also try to minimize the difference between student and teacher prediction.
Theoretical reason behind this approach lies in the fact that predictions from teacher ranker contain more information than user defined {0,1} labels. For instance, a soccer fan may not like a particular soccer related item explicitly, however a teacher ranker may be able to identify that the item is soccer related and the user is a soccer fan, and hence may produce a higher score for the item as compared to, let's say, a item related to tennis.
A smaller student model on its own, without soccer related features, may not be able to identify that the item is soccer related and hence produces a lower score, on par with tennis items. With scores from teacher ranker, however, the student ranker will know that it needs to produce a higher score as compared to tennis items even though the hard label is 0.
Approaches to Knowledge Distillation
Below I describe the three approaches that can be used for KD.
Frozen teacher
In this approach the teacher model is frozen and its predictions are logged for using as “soft” labels for training the student model. Particularly, one tries to minimize the difference between the teacher prediction and the student predictions. For binary labels, one can formulate the loss using KL divergence:
As discussed above the main advantage of this approach is that the student model learns directly from non-binary predictions of the teacher model which may carry more information than binary hard labels.
On the other hand, however, the student model may also get to any overfitting in the teacher model, and hence lose some generalization capabilities. One way to address this is adding the hard label loss as a regularization term:
Where 𝜆 is regularization parameter, and y denotes the binary hard labels. Another way to achieve this is co-training as described below.
Co-training
In this approach both teacher and student models are trained simultaneously on the hard labels. Particularly, here the loss becomes :
As KL divergence is unsymmetric one can also use symmetric divergence to make the equation symmetric by adding
to the equation. The main advantage of this approach that it provides the hyper parameters 𝜆1 and 𝜆2 which can be used to balance the overfitting and under fitting in both teacher and student model, and thereby improving both as opposed to the frozen teacher approach.
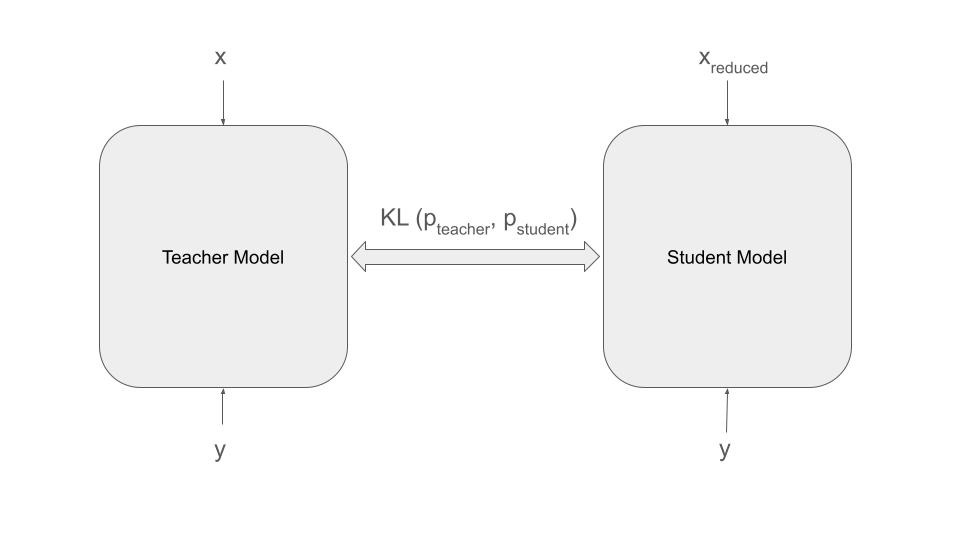
However one disadvantage here is that the model size gets bigger, and simultaneous training may require bigger machines, which may not always be possible as GPUs have finite memory.
One way to go around this constraint is to share neural networks between teacher and the student model, for instance embedding the student model within the teacher model as shown in the figure below.

Issues in product-ionizing
While KD works theoretically and shows improved performance many times. In a production setting we need to be careful to achieve success. Particularly in many production RecSys LSR and ESR are trained on different objectives, or they may diverge in future as new changes are pushed to production. Hence using LSR as a teacher can degrade performance of ESR and may become an impediment to parallel improvements.
One way to avoid such conflict is to use a separate teacher model, and keep it aligned with the ESR model objective. One can also align LSR with this teacher periodically to improve LSR performance. However, this comes with an additional cost of maintaining and training an additional teacher mode which may not always be desirable.
Another way to avoid such mismatch is to consciously align the training objectives of the ESR and the LSR by building tightly coupled teams and setting up alerts/alarms on when such objectives change.
Conclusion
In conclusion KD is a powerful technique to improve the performance of RecSys. It comes in various flavors, allowing companies to pick and choose depending on their needs. Although powerful productionizing KD has some challenges, which should be kept in mind to build a successful RecSys.
Disclaimer: These are the personal opinions of the author. Any assumptions, opinions stated here are theirs and not representative of their current or any prior employer(s).
[
This is a great review paper for both frozen and co training approaches. They called it offline vs online https://arxiv.org/pdf/2006.05525.pdf
Great post! Do you have any (public) references on frozen teacher and co-training approaches? Did anyone launch this successfully?